
Intel Beyond 2025: 5 Nodes In 4 Years (Part 2)
A Hitchhiker's Guide to RibbonFET, PowerVia, EUV, EMIB and Foveros


Firstly, some good news. There is finally light at the end of the tunnel for the PC CPU sector after a multi-year drought. Semiconductor industry analysis firm Canalys announced earlier this month that sector PC volumes declined by just 7% YoY in 3Q23 — marking the smallest contraction in over a year. Most of the industry pessimism over the past year has been due to PC OEMs burning through their excess inventory — it seems that the sector as a whole has finally hit an inflection point, and that this is the beginning of the end for the PC CPU slump. There is a widespread market expectation that the worst could be over for PC vendors by end-2023, as evidenced by the following quote by Mikako Kitagawa, research director at Gartner:
“The good news for PC vendors is that the worst could be over by the end of 2023,” Kitagawa said. “The business PC market is ready for the next replacement cycle, driven by the Windows 11 upgrades. Consumer PC demand should also begin to recover as PCs purchased during the pandemic are entering the early stages of a refresh cycle.”
The analogy I would draw to INTC 0.00%↑ today would be Buffett’s acquisition of Apple in 2016. When Buffett started acquiring his Apple stake in 2016 at just 8.8x PE, it pretty much represented the point of maximum pessimism for Apple — at the time it could do no right, and nothing was ever good enough. Given the similarly shaped clouds hanging over Intel, it’s not entirely impossible to imagine INTC 0.00%↑ being in the same position today.
“Price is what you Pay, Value is what you Get” — Warren Buffett
‘5 Nodes In 4 Years’ Intel Masterplan

When Pat Gelsinger re-joined Intel as CEO, he was likely given a mandate by the US government to secure US national strategic interests within the semiconductor value chain. With only three leading-edge fabs across the entire planet (TSMC, Samsung and Intel) and just one EUV equipment manufacturer (ASML), this meant that Intel had to catch up to TSMC and Samsung — if only for contingency purposes, and quickly. This national strategic interest is also why I describe IFS as the “Lockheed Martin of Tomorrow”.
We’ll discuss IFS’s business significance to Intel further in Part 3 — but as IFS will also be the contract foundry of Intel’s fabless operations going forward, this automatically implies that IFS has to catch up to TSMC’s process nodes. In response, Intel announced its “5 Nodes In 4 Years” masterplan — which involves regaining transistor performance and power (performance per watt) leadership by end-2025. Of course execution risk is always going to be an uncertainty — but if anyone can do it, it’s Intel.
In this section, I’ll provide a detailed explanation of what “5 Nodes In 4 Years” entails and how it relates to market competitiveness vs. incumbents (i.e. TSMC and Samsung). It will also provide additional context to the future performance trajectory of Intel’s CCG segment as described in Part 1.
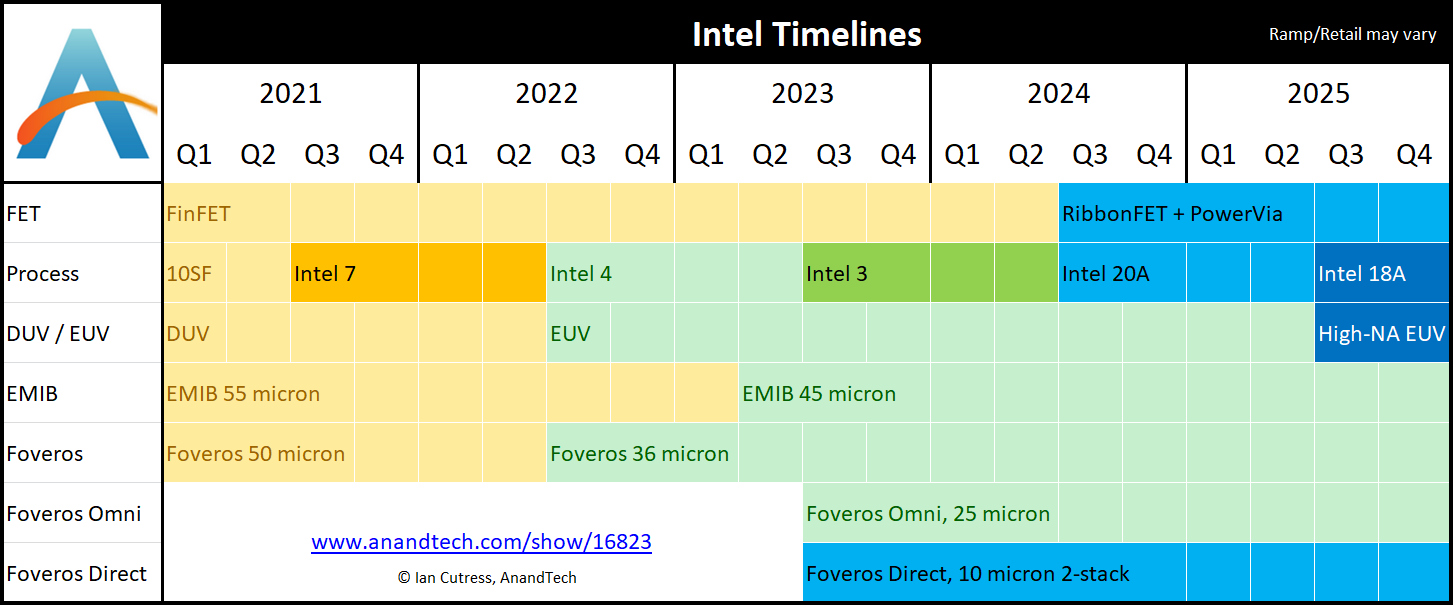
Let’s bring back the process node chart from above. My intention here is to explain all the concepts in this chart to a sufficient degree, such that newcomer investors are able to understand all the business and competitive implications of “5 Nodes In 4 Years”. As this is an Intel investment primer, we won’t be diving too deep into the technical engineering side — but I’ll explain it in enough detail such that a businessman will be able make a financial decision.
As you can see from the chart above, Intel plans to erase its existing lag to the industry by attaining 5 manufacturing nodes worth of progress by end-2025 — which is half of the reason why I titled this report “Intel Beyond 2025” (the other half is due to IFS, which is expected to pick up full steam by 2026). The “Process” row describes the nodes themselves (i.e. naming) — while the other rows describe the semiconductor technology which those processes encompass. If you have the time, this is a great article which explains all of them — but if you’re time-strapped, you’ll find a more succinct explanation of each of them below:
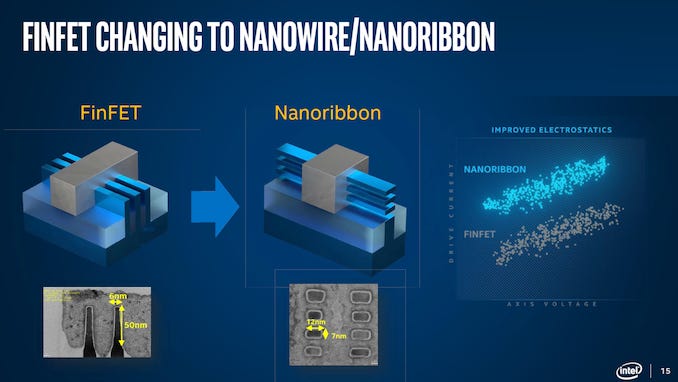
FET: When you hear about “7nm” or “5nm”, that nomenclature is based on a legacy manufacturing process called MOSFET. MOSFET is a 2D/planar process, and if you imagine the 2D surface of a semiconductor chip, the number of transistors you can cram onto a chip is directly proportional to the size of each transistor — e.g. a 14nm process will yield double the number of transistors as a 28nm process. However, most chips today are manufactured using MOSFET’s successor called FinFET which is a 3D process — hence this “nm” scaling no longer makes sense. In fact, the Big 3 fabs are already taking their first steps into the 4D process successor to FinFET, called Gate All Around (GAA). Intel’s marketing term for GAA is RibbonFET, which they will start using for Intel 20A in 3Q24 as we can see above; TSMC plans to use GAA for its 2nm class process slightly ahead of Intel’s; while Samsung has already begun using GAA for its 3nm class process.
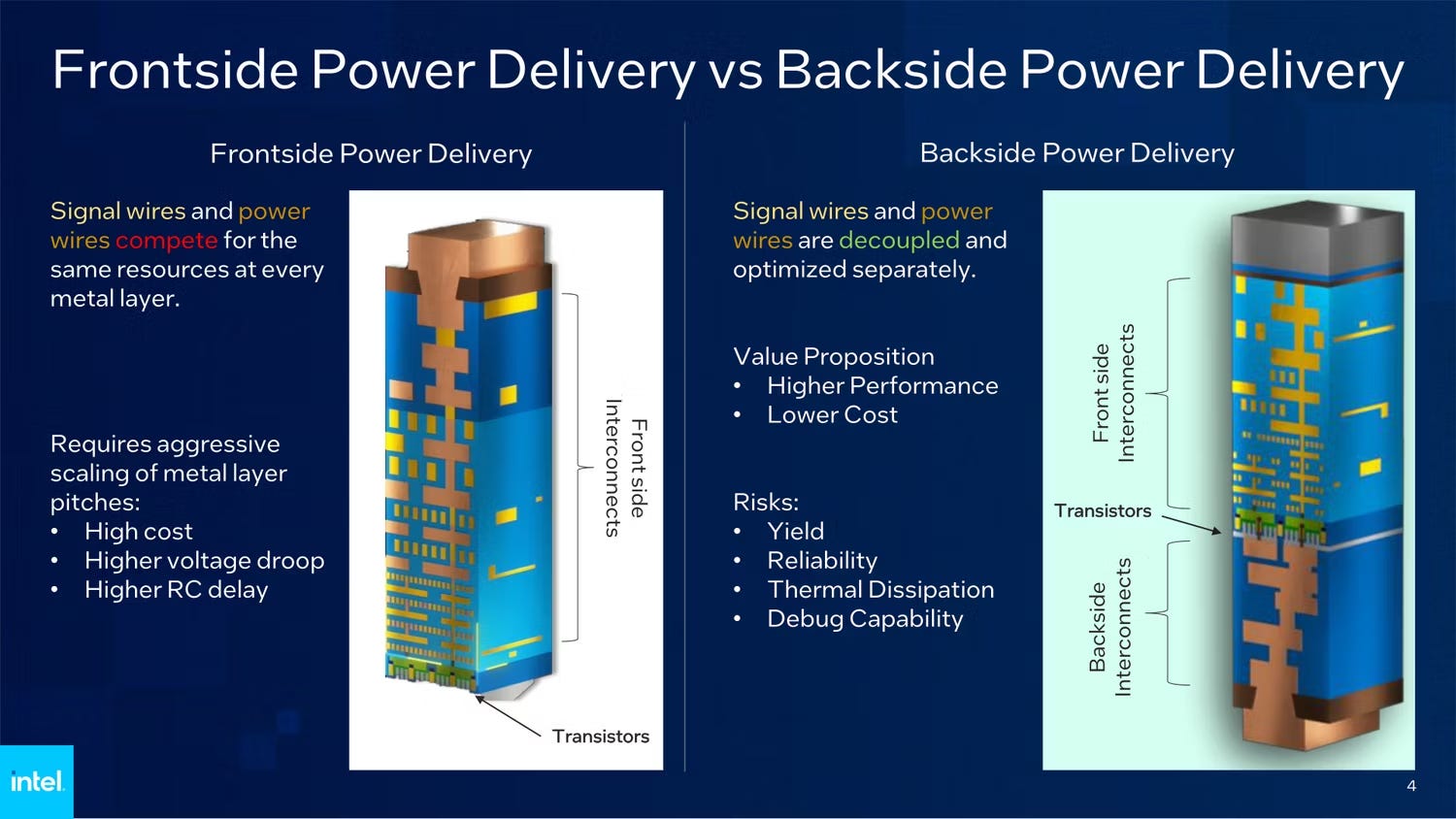
PowerVia: PowerVia is Intel’s marketing term for a revolutionary new semiconductor technology called backside power delivery. Importantly, Intel is expected to release this years ahead of both TSMC and Samsung — which should lead to more competitive pricing on chips with better performance per watt. As the name implies, backside power delivery involves delivering power to a chip via the “backside” of a chip. Currently, semiconductors deliver power to transistors through the same “highway” as other ancillary functions (“frontside”) — which can lead to signal interference and deterioration. Backside power delivery sandwiches the transistor layer between the non-transistor layer (where ancillary functions are located) and the “power” layer (where the chip is connected to external power source) — so that the “power highways” can be separately placed on the “backside” of the chip away from the “signal highways”, resulting in lower signal interference and more efficient energy use. Importantly, this is non-trivial for TSMC and Samsung to replicate because backside power delivery normally leads to greater thermal issues — which Intel has apparently managed to solve ahead of the competition. PowerVia represents a genuine competitive advantage for Intel.
Process: In the chart above, we can see the timeline that Intel plans to attain each upcoming process node under their “5 Nodes In 4 Years” masterplan. For instance, their upcoming Meteor Lake chip is based on the Intel 4 manufacturing process (equivalent to TSMC “5nm” or N5) and will be released in 3Q23. The “A” in Intel 20A and 18A both refer to “Angstrom”, which is 0.1 nm — hence 20A implies 2nm, while 18A implies 1.8nm.
DUV/EUV: DUV is the predecessor of EUV, and stands for “Deep Ultraviolet” while EUV stands for “Extreme Ultraviolet”. All you really need to know is that EUV is a much smaller beam with a wavelength of just 13nm; while DUV has a wavelength of 193nm, nearly 15x larger. Obviously, the smaller the beam the greater the transistor density that the manufacturing process is capable of producing. High-NA EUV is just an advanced version of EUV, which supposedly has a wavelength up to half of regular EUV. If you’d like to know more, head over to the Equipment & Software section of last week’s semiconductor industry primer.
EMIB (Advanced Packaging): The easiest way to understand EMIB is “horizontal stacking” — as opposed to Foveros, which is most easily described as “vertical stacking”. If you’ve ever wondered why manufacturers don’t just make larger chips to accommodate more transistors on a single chip, it’s because there is a physical limit to how large you can make a chip before you run into thermal and signal interference issues. EMIB circumvents this limit by joining two chips together, and having them communicate with each other to simulate being one giant chip (e.g. Apple M1 Ultra). However, such a “double-chip’s” performance is limited by the speed at which the interconnect which joins them can transmit data — these interconnects can usually either be produced cheaply or transmit data fast, but not both. EMIB is Intel’s proprietary interconnect solution which gets around this limitation by making a thin “bridge” which talks fast, while having the rest of the interconnect made with cheap materials — thus being both relatively cheap to produce, while also being able to transmit data relatively fast at the same time.
Foveros (Advanced Packaging): As alluded to above, the easiest way to conceptualize Foveros is to describe it as “vertical stacking”. While the underlying engineering is world’s apart from EMIB, it’s basically just EMIB on the vertical plane in practice (i.e. die-to-die-stacking). The main reason why chips are not typically stacked vertically on top of each other is because 1) it doesn’t allow enough heat to escape; and 2) the bottom die runs into the same signal interference issues as described in the PowerVia section above, when power is channeled through the bottom die to the top die. Foveros gets around the heat issue by moving most of the logic components of the bottom die to the top die (and vice versa for non-logic components), so that excess heat trapped between the two dies only affects non-logic components on the bottom die. It also circumvents the signal interference issue by introducing tiny nanowires which run the entire vertical length of the two dies called “through-silicon-vias” (TSVs). TSVs carry power separately to the top die while bypassing the regular power “highways” of the bottom die (ala PowerVia) — thus reducing signal interference issues in the bottom die.
Foveros Omni: Foveros Omni is just 3rd-gen Foveros, otherwise known as “cantilevered silicon”. With “vertical stacking” in regular Foveros, one issue is that there is a limit to how much power you can deliver to the top die without causing signal interference issues in the bottom die — TSVs notwithstanding. Omni solves this by making the top die larger than the bottom die, and then placing TSVs on the outside circumference of the top die so that they “hang off the ledge”. These TSVs can then bypass the bottom die and be connected directly to the external power source underneath without having to go through the bottom die, thus solving any potential signal interference issues caused by channeling excess power through the bottom die to the top die. Foveros Omni also allows chips of different sizes to be vertically stacked, where previously both the top and bottom dies would need to be of identical size — further augmenting chiplet modularization and improving performance efficiency.
Foveros Direct: Direct refers to 4th-gen Foveros. In both EMIB and Foveros, the maximum speed at which the stacked chips can communicate with each other (bandwidth) through the interconnect is a performance limitation. This is because the interconnects between the chips are usually some form of copper connects soldered with tin called “bumps” — and the bandwidth is limited by the number of bumps along the edge of both chips, the more the better. Foveros Direct gets around this limit by replacing the bumps with super-flat edge-to-edge copper connections along the edges of both chips — which in theory implies an infinite number of bumps, but in practice is not perfectly flat. Given how much surface area of both chips are touching each other when they are vertically stacked, you can see how such an edge-to-edge copper connection as introduced by Foveros Direct can significantly bump up bandwidth performance.
The following chart describes the equivalent progress made in each of the above manufacturing processes between the Big 3 fabs — Intel, TSMC, and Samsung. We can see below how Intel has just caught up to TSMC in its Foveros Direct equivalent, and is behind both of them in GAA; but is currently ahead of both TSMC and Samsung in their EMIB and Foveros Omni equivalents. The simplified end-interpretation that we can make is that over the LT, all three are pretty much neck-and-neck in terms of process nodes advantages, with a maximum of only 1-2 years gap in between them across the entire process node stack.
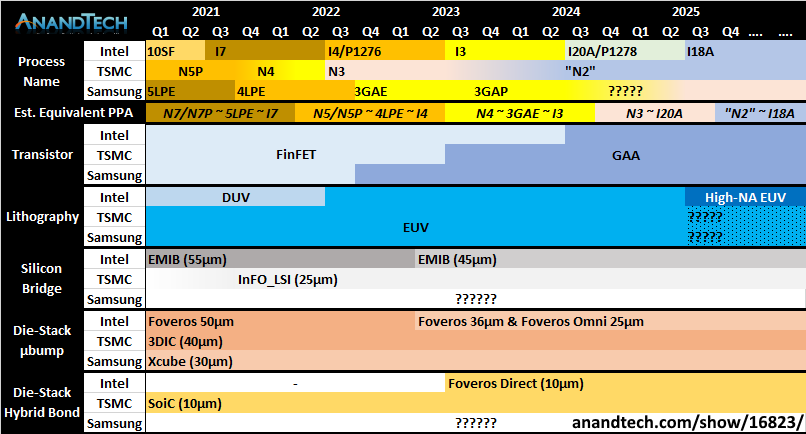
I’m 99% sure that I’ve managed to butcher at least one of the descriptions above, and that the real semiconductor engineering pros are probably shaking their heads as they read this section. But remember, this is meant to be an Intel investment primer not a semiconductor engineering primer — and I think I’ve done an adequate job laying out the investment context of Intel’s “5 Nodes In 4 Years” masterplan, descriptive mistakes notwithstanding.
Intel Part 3 report
In the upcoming Part 3 report, we’ll dive into the future of Intel IFS, the macro theater surrounding it, and see how IFS alone could potentially justify INTC 0.00%↑’s entire market cap of $150B. Click the link below to read it now… or refresh your memory of Intel’s business units in Part 1!
Intel Foundry Services: America’s TSMC (Part 3)

The Unassailable Moats & Wonderful Business of Leading-Edge Semiconductor Fabs (only 3 on Planet Earth) + How IFS Alone Can Justify $INTC's $150B Market Cap By Itself
Intel Beyond 2025: Ultra Broad-Dive Primer - Could Intel One Day Disrupt NVIDIA in AI Hardware? (Part 1)

Centrino Revolution 2 + Edge AI: Raft of Enablement + AI Everywhere + IFS = Lockheed Martin of Tomorrow + AI Rising Tide Lifts All Boats... including CPU TAM??
Why $INTC Only Fell By -3% on Yesterday's Announcement of NVIDIA's ARM-based PC Chips

What Value Investing Looks Like When Properly Implemented, In Real-Time
Semiconductor Industry Primer

This Semiconductor Industry Primer will help you understand each of the 5 stages of the leading-edge semiconductor industry's supply chain — and why Intel is the Lockheed Martin of Tomorrow in the Western Hemisphere.
Check out some of our earlier stock reports!







